
kubeadm1.13.3升级1.13.4
https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm-upgrade/
检查可用于升级的版本,并验证当前群集是否可升级
[root@k8s-master ~]# kubeadm upgrade plan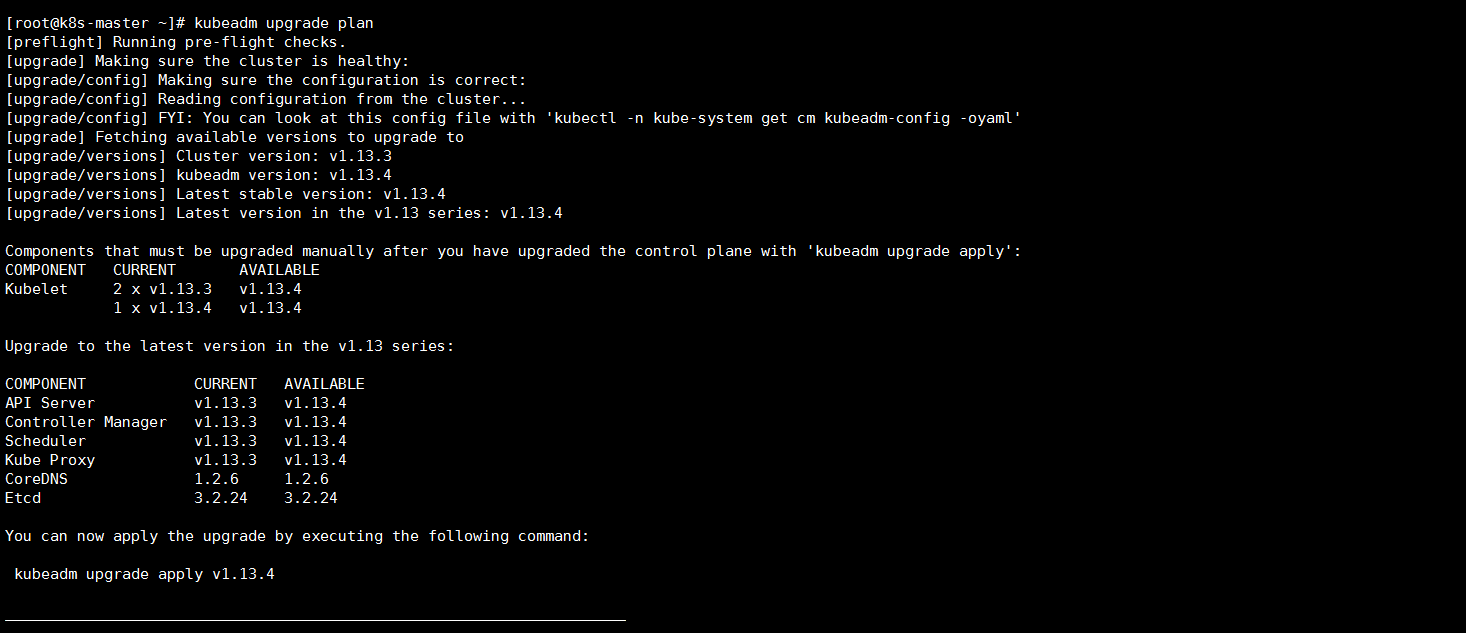
查看集群版本
[root@k8s-master ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master Ready master 68m v1.13.4
node1 Ready <none> 68m v1.13.3
node2 Ready <none> 66m v1.13.3
在每个 $NODE 节点上升级 Kubernetes 软件包版本 kubelet kubeadm kubectl
查看可用版本
yum list –showduplicates | grep ‘kubeadm\|kubectl\|kubelet’
yum install -y kubelet kubeadm kubectl
查看版本的容器镜像版本:
[root@k8s-master ~]# kubeadm config images list
由于默认镜像站被墙使用首先的去其他镜像站拉取镜像修改tag
#!/bin/bash
images=(kube-apiserver:v1.13.4 kube-controller-manager:v1.13.4 kube-scheduler:v1.13.4 kube-proxy:v1.13.4 pause:3.1 etcd:3.2.24)
for imageName in ${images[@]} ; do
docker pull mirrorgooglecontainers/$imageName
docker tag mirrorgooglecontainers/$imageName k8s.gcr.io/$imageName
docker rmi mirrorgooglecontainers/$imageName
done[root@k8s-master ~]# docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
calico/node v3.4.3 b6a9f04ba7af 4 days ago 79.6MB
calico/cni v3.4.3 87d1d0426f56 4 days ago 75.4MB
calico/kube-controllers v3.4.3 57718fa8402d 4 days ago 56.5MB
k8s.gcr.io/kube-proxy v1.13.4 fadcc5d2b066 13 days ago 80.3MB
k8s.gcr.io/kube-apiserver v1.13.4 fc3801f0fc54 13 days ago 181MB
k8s.gcr.io/kube-controller-manager v1.13.4 40a817357014 13 days ago 146MB
k8s.gcr.io/kube-scheduler v1.13.4 dd862b749309 13 days ago 79.6MB
将Kubernetes群集升级到指定版本
kubeadm upgrade apply v1.13.4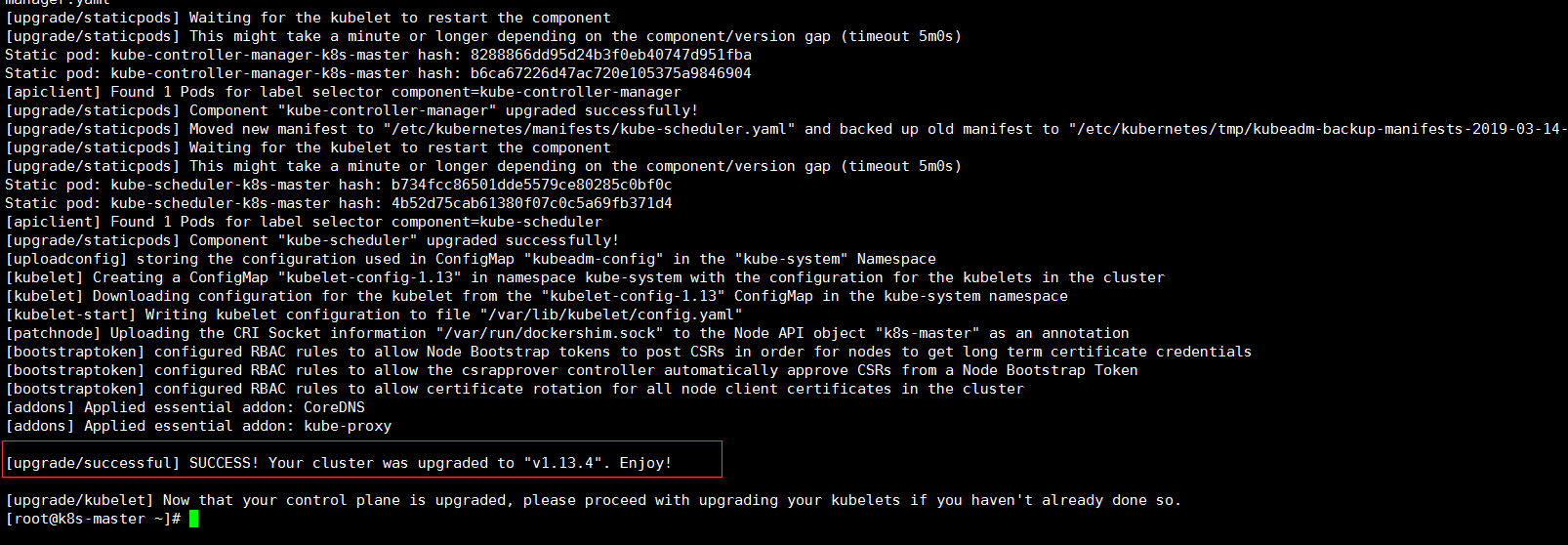
升级主节点和其他节点
准备为每个节点进行维护,将其标记为不可调度并移出工作负载:
kubectl cordon $NODE
kubectl drain $NODE --ignore-daemonsets
在 master 节点上,您必须增加 --ignore-daemonsets忽略了所有的daemonset的pod,并且将剩余的pod驱逐;
在除主节点之外的每个节点上,升级 kubelet 配置:
kubeadm upgrade node config --kubelet-version $(kubelet --version | cut -d ' ' -f 2)
重启 kubelet 进程:
systemctl restart kubelet
kubectl uncordon $NODE再次验证 kubectl get nodes


